Google Docs для парсинга
Функциями importHTML, importXML
Функция importHTML
С помощью функции importHTML можно настроить импорт данных из таблицы или списка на странице сайта.
Синтаксис
=IMPORTHTML(ссылка; запрос; индекс)
- ссылка — ссылка на веб-страницу, включая протокол (http:// или https://),
- запрос — значения «table» или «list», смотря, что нужно парсить (таблицу или список),
- индекс – порядковый номер списка или таблицы (отсчет начинается с 1).
Пример:
IMPORTHTML("http://ru.wikipedia.org/wiki/Население_Индии"; "table"; 4)
Переменные можно разместить в ячейках, тогда формула изменится так:
IMPORTHTML(A2; B2; C2)
Примеры использования importHTML
Выгрузка любых табличных данных
Однажды мне понадобилось собрать список минус-слов по городам России в существительном падеже. Первые пару нагугленных файлов с минус-словами были неполными, а в других меня не устроила словоформа. Поэтому я просто решил спарсить страницу Википедии, что заняло около двух минут, включая время на открытие Гугл Таблицы, поиск нужной страницы Википедии и настройку формулы. С этого примера я и начну.
Задача: выгрузить список всех городов России со страницы https://ru.wikipedia.org/wiki/Список_городов_России
Чтобы выгрузить данные из этой таблицы нам нужно указать в формуле ее порядковый номер в коде страницы. Чтобы этот номер узнать, нужно открыть код сайта (в нормальных браузерах это сочетание Ctrl+U, либо клавиша F12, открывающая панель разработчика). А дальше поиском по коду определить порядковый номер:
В данном случае целевая таблица является первой в коде.
Составляем формулу:
=IMPORTHTML("https://ru.wikipedia.org/wiki/Список_городов_России";"table";1)
Результат:

Выгрузка данных из списка
Как-то я работал с интернет-магазином у которого была обширная структура и очень неудобное меню. Надо было бегло оценить текущую структуру сайта, чтобы понять ассортимент и возможные очевидные проблемы, типа дублирования пунктов меню. Меню было реализовано в виде списка, чем я и воспользовался. Меньше чем через минуту полная иерархия сайта отображалась у меня в Гугл Табличке.
Задача: выгрузить все пункты меню, оформленного тегами <ul>...</ul>.

Как и в первом примере для формулы понадобится определить порядковый номер списка в коде сайта. В данном случае — четвертый.

Составляем формулу:
=IMPORTHTML("https://tools-markets.ru/";"list";3)
Результат:

Списки и таблицы — это хорошо, но чаще всего необходимо выдернуть с сайта информацию, оформленную другими тегами. Например, тексты, цены, заголовки и так дальше. Эти данные можно спарсить, используя формулу importXML, разберем ее подробнее.
Функция importXML
С помощью функции importXML можно настроить импорт данных из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML.
По сравнению с importHTML у данной функции гораздо более широкое применение. Она позволяет собирать практически любую информацию со страницы/документа, от частичных фрагментов до полного ее содержания. Ниже будут описаны примеры парсинга HTML-страниц сайта. Парсинг по файлам рассматривать не стану, т.к. такая задача возникает редко и большинство из вас с этим не столкнется никогда. Но если что, принцип работы везде одинаковый, главное понять суть.
Синтаксис
IMPORTXML(ссылка; "//XPath запрос")
- ссылка – адрес веб-страницы с указанием протокола (http:// или https://). Значение этого параметра должно быть заключено в кавычки или представлять собой ссылку на ячейку, содержащую URL страницы.
- //XPath запрос – то, что будем импортировать. Ниже мы разберем основные примеры запросов (а тут подробнее про XPath).
Пример:
IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing"; "//a/@href")
Значения переменных можно хранить в ячейках, тогда формула будет такой:
IMPORTXML(A2; B2)
Примеры использования importХML
Пример 1. Импорт мета-тегов и заголовков со страниц
Самая простая и распространенная ситуация, которая может быть — узнать мета-теги или заголовки продвигаемых страниц. Для этих целей лучше подходит парсинг сайта специализированным софтом типа Comparser'a. Но бывают и исключения, например, если сайт очень большой и это сделать затруднительно, либо у вас нет под рукой программы. Или если вы собираетесь дальше использовать полученные данные в таблицах для мониторинга изменений мета-тегов и сверки целевых и фактических мета-тегов на страницах.
Формулы простые.
Получаем title страницы:
=importxml(A3;"//title")

Получаем заголовки h1:
=importxml(A3;"//h1")

Получаем description:
=importxml(A3;"//meta[@name='description']/@content")

Последняя формула получилась сложнее т.к. нас интересует значение не самого тега, а его атрибута:
- ищем тег meta //meta
- у которого есть атрибут name='description' [@name='description']
- и парсим содержимое второго атрибута content /@content
Пример 2. Определяем наличие текста на странице и его длину в символах
Этот пример мне помог при работе с проектом, тексты для которого писал и размещал сам клиент, и ему было чрезвычайно лень сообщать мне о ходе процесса. Небольшой лайфхак с Гугл таблицами позволил мне мониторить динамику его работы, а ему с чистой совестью и дальше продолжать лениться и не сообщать мне ничего.
Рассмотрим ситуацию на примере нашего блога http://alaev.info, а конкретно на странице https://alaev.info/blog/post/6202. Если заглянуть в код, то мы увидим, что контент страницы расположен в теге <div> с классом entry.
Формула:
=LEN(concatenate(IMPORTXML(A1;"//div[@class='entry']")))
В ячейке А1 у нас ссылка на статью, в запросе XPath мы получаем содержимое тега div, у которого есть класс entry, то есть парсим весь текст страницы: =IMPORTXML(A1;"//div[@class='entry']")
Функция CONCATENATE (в русском варианте СЦЕПИТЬ) нужна, чтобы объединить все абзацы в один кусок контента. Без нее мы посчитаем только объем первого абзаца.
Функция LEN (в русском варианте ДЛСТР) считает количество символов.

Пример 3. Выгружаем актуальные цены
Однажды потребовалось не только заниматься оптимизацией сайта, но и следить за ценами конкурентов по схожим товарным позициям. Использование специализированного софта и сервисов я практически сразу отмел, т.к. специальные сервисы по мониторингу не укладывались в бюджет, а вручную сканировать сайты конкурентов несколько раз в неделю не комильфо.
К счастью, вариант с Гугл доками оказался подходящим и уже к концу дня я все настроил так, что данные подтягивались автоматически. От меня ничего не требовалось, кроме как отправить ссылку на документ клиенту и спокойно заниматься своими делами.
Я решил рассмотреть похожую ситуацию на случайном сайте. Итак, допустим, мы хотим мониторить цены на автомобили и, скажем, выгружать актуальные цены с сайта http://centrmotors.lada.ru/. Вот пример товарной карточки http://centrmotors.lada.ru/ds/cars/granta/sedan/.
Чтобы настроить формулу снова идем в код сайта и смотрим в каких тегах располагается цена. Примеры должны быть простыми, поэтому я буду выгружать только минимальную цену.

На данном сайте нам надо парсить содержимое тега <span> с id textspan7.
Формула:
=importxml(A2;"//span[@id='textspan7']")
В таблице ссылки на товары укажем в столбце А, а формулу вставим в столбец В.
Результат:

Поясню:
- A2 — номер ячейки из которой берется адрес страницы,
- //span[@id='textspan7'] — блок из которого будем выводить информацию.
- Если бы у нас вместо span был div, а вместо id был бы class, то вторая часть формулы была такой:
//div[@class='textspan7']
Автоматизируем дальше.
Приведенное выше решение не идеальное, ведь нам надо предварительно собрать адреса товарных страниц, а это довольно муторно. Если на сайт добавят новые модели авто, то информация по ним не будет подгружаться в таблицу т.к. адреса страниц будут отсутствовать в документе.
Подключив логику и другие формулы, можно хакнуть рутину. Ссылки на все модели присутствуют в главном меню. А если есть ссылки, то скорее всего их тоже можно спарсить.

И действительно, заглянув в код, мы увидим, что ссылки на товарные страницы располагаются в теге <p> c классом CMtext4:

Формула:
=IMPORTXML(A8;"//p[@class='CMtext4']/a/@href")
- A8 – в этой ячейке ссылка на сайт,
- p[@class='CMtext4'] – тут мы ищем содержимое тега <p> с классом CMtext4,
- /a/@href – а в этой части формулы мы уточняем, что из содержимого <p> хотим достать содержимое вложенного тега <a>, а если еще точнее, то ту часть, которая прописана в href="".
После применения формулы в документе получится такой список:

Мы получили ссылки на все товары, которые нас интересуют. Осталось настроить парсинг цен по этим адресам. Но ссылки на страницы относительные, а нам обязательно нужны абсолютные ссылки, включающие имя домена. Чтобы подставить в ссылку домен используем функцию CONCATENATE.
Формула:
=IMPORTXML(concatenate("http://centermotors.lada.ru";A9);"//span[@id='textspan7']")
Либо при условии, что у нас в ячейке А8 находится адрес домена:
=IMPORTXML(concatenate(A$8;A9);"//span[@id='textspan7']")
Размещаем мы ее справа от первой ссылки на товарную страницу и протягиваем вниз для всех ссылок или до конца листа на случай, если в будущем будет больше товаров.

Результат:

Поясню, если кто-то еще не разобрался:
- A$8 — ячейка, в которой указан домен сайта. Знаком $ фиксируем строку, чтобы это значение не изменилось, когда мы начнем протягивать формулу вниз.
- A9 — это первый URL товарной страницы, при перетаскивании формулы значение автоматически меняется, т.е. в 10 строке у нас вместо A9 будет A10, в 11 строке A11 и т.д.
Теперь если на сайте будут добавлены или удалены товары, то в нашем файле ссылки на них автоматически обновятся, и мы будем всегда видеть только актуальную информацию.
Пример универсальный и имеет применение не только в рабочих целях. Например, можно мониторить цены на товары в ожидании скидок. А если еще немного потрудиться, то и настроить оповещение на почту при изменении цены (или любого другого значения) ниже/выше определенного значения.
Пример 4. Узнать количество товаров в категориях
Очень полезный прием для тех, кто хоть раз продвигал интернет-магазины без товаров. Нет, это не шутка! Мне доводилось пару раз, как бы это смешно ни звучало.
Например, движок сайта не отображает те товары, которых нет на складе (или сам клиент может удалять их вручную). В этом случае есть риск возникновения ситуации, когда на складе вообще не окажется определенного типа товаров и категории будут висеть пустые, в лучшем случае на странице будет текстовое описание.
Но с помощью парсинга легко узнать на каких страницах есть беда с ассортиментом.
Для примера возьмем сайт http://bz2.ru. Категории с товарами выглядят вот так http://bz2.ru/katalog/generatory-dizelnye/dizelnye-generatory-100-kvt/.
Чтобы посчитать количество товаров идем в код сайта и смотрим какими тегами оформлены товары.

Товар оформлен в теге <div> с классом product, заголовок товара оформлен в теге <div> с классом title. Я решил посчитать заголовки:
Формула:
=COUNTA(IMPORTXML(A3;"//div[@class='title']"))
Результат:

COUNTA нужна, чтобы подсчитать число значений, если бы мы не использовали эту функцию, то результат был бы таким:

Как и в примере выше, можно автоматизировать процесс, чтобы ссылки на все категории парсились автоматически и их не приходилось добавлять вручную.
Пример 5. Парсим код ответа сервера
Я очень редко встречаю сайты, где что-то постоянно отваливается, но все же бывает. В случае необходимости можно быстро проверить все продвигаемые страницы на доступность и корректный ответ сервера.
Обычно я такие вещи мониторю с помощью скриптов без использования формул, но с помощью рассматриваемой функции это можно реализовать. Данный способ, пожалуй, единственное исключение из общего списка примеров, потому что я к нему не прибегал ни разу, но уверен, что кому-то из вас он пригодится.
В сети много сервисов, которые проверяют страницы на код ответа сервера. Суть идеи в том, чтобы парсить данные с такого сервиса. Для примера я решил взять самый популярный — http://www.bertal.ru/ — если мы проверим в нем страницу, то он отобразит результат по URL вида https://bertal.ru/index.php?a4789763/alaev.info/blog/post/6202#h.
Я не знаю, что означают символы a4789763, но на результат они не влияют. Смотрим:

Формула:
=importxml(concatenate(A$4;A6);"//div[@id='otv']/b")
Результат:

- A$4 — адрес ячейки с неизменяемой частью URL,
- A6 — ячейка с адресом страницы, код ответа, которой хотим проверить.
Функцией CONCATENATE склеиваем наши куски в один URL с которого и парсим данные.
Пример 6. Узнаем количество страниц в индексе ПС
Если мы введем в поисковик запрос типа [site:http://alaev.info], то узнаем сколько всего страниц данного сайта находится в выдаче.

Результаты будут выведены на странице типа https://yandex.ru/search/?text=site%3Ahttp%3A%2F%2Falaev.info&lr=213, где после [https://yandex.ru/search/?text=site%3A] следует адрес сайта и необязательный параметр региона поиска [&lr=213].
Все, что нам нужно — это сформировать URL, по которому поисковик отдаст нам ответ, и определить из каких тегов парсить эту инфу.
В данном случае данные лежат в теге <div> с классом serp-adv__found.
Если мы поместим ссылку на сайт в ячейку A15, то формула будет такая:
=importxml(CONCATENATE("<a href="https://yandex.ru/search/?text=site%3A%22;A15">https://yandex.ru/search/?text=site%3A";</a>A15);"//div[@class='serp-adv__found']")
Результат:

В таком виде результат не особо ценен, т.к. желательно не только узнать количество страниц, но и провести какие-то дальнейшие вычисления или сравнения. Для этого модернизируем формулу и приведем текстовое значение в числовое.
Для этих целей будем использовать функцию SUBSTITUTE (в русском варианте ПОДСТАВИТЬ). Суть идеи в том, чтобы убрать слово [Нашлось: ] и заменить надпись [тыс. результатов] на [000], чтобы в итоге надпись выглядела как просто число 2000.
Но есть нюанс. Окончание меняется в зависимости от результата, например, может выглядеть как [Нашёлся 1 результат], поэтому такие вариации тоже надо будет заменить.
Не буду вас утомлять, поэтому ближе к делу: сначала заменим надпись [Нашлось: ] на пустоту вот так:
=SUBSTITUTE(ссылка;"Нашлось ";"")
Дальше заменим [тыс. результатов] на [000] для этого добавим еще одну аналогичную функцию, и формула будет выглядеть так:
=SUBSTITUTE(SUBSTITUTE(ссылка;"Нашлось ";"");"тыс.";"000")
Проделаем тоже самое для остальных вариантов и вместо слова [ссылка] пропишем функцию импорта. Конечная формула будет следующей:
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(importxml(CONCATENATE("https://yandex.ru/search/?text=site%3A";A10);"//div[@class='serp-adv__found']");"Нашлось ";"");" результатов";"");" результата";"");" ";"");"Нашлась";"");"результат";"");"Нашёлся";"");"тыс.";"000")
Немного пугающе, правда? Возможно, есть более элегантные решения, но так как данный вариант универсальный и полностью рабочий, то я остановился на нем. Если вы найдете более красивое решение, то поделитесь в комментариях, мне будет интересно увидеть другие возможные построения формулы.
находим сайт, на котором есть необходимая нам информация. Вводим два города, а расстояние должно расположиться в третьей ячейке таблицы. Что сделать, чтобы спарсить часть нужной нам информации в таблицу Google? Использовать importxml.
Определяем, в каких HTML-тегах заключена нужная нам информация
1. Кликаем правой кнопкой мыши на заголовке с расстоянием и выбираем «Просмотр кода элемента». Необходимая строка заключена в html-тэге h1.
2. Проверяем адрес страницы — он имеет подходящий вид (http://marshrut.su/rasstojanie/mezhdu-gorodami/mezhdu-gorodami?ot=Астана&do=Варшава).
3. Формируем URL с помощью оператора «concatenate» — склеиваем части адреса и введенные нами города.
=concatenate("http://marshrut.su/rasstojanie/mezhdu-gorodami/?ot=";A3;"&do=";B3)4. Используем «importxml» — первым аргументом будет «concatenate» (формируемый им URL), вторым — простое выражение на xPath — «//h1». Так мы указали, что необходимо спарсить в ячейку таблицы все заголовки h1. Нам повезло — такой заголовок используется один раз на странице, поэтому нам не придется обрабатывать массив данных.
=importxml(concatenate("http://marshrut.su/rasstojanie/mezhdu-gorodami/?ot=";A3;"&do=";B3); "//h1")5. Получаем всю строку «Расстояние от… до… км». Обрезаем лишнее из этой строки с помощью «mid». Чтобы вычислить длину отрезка, который необходимо сократить, определим длины названий городов с помощью «len» и просуммируем с длинами других слов. Получаем конечную формулу:
=mid(importxml(concatenate("http://marshrut.su/rasstojanie/mezhdu-gorodami/?ot=";A3;"&do=";B3); "//h1");len(B3)+len(A3)+19;10)Теперь можем ввести сколько угодно пар городов, «протянуть» ячейку C2 вниз и моментально получить все расстояния между этими городами.

Парсинг данных с помощью Kimono
https://chrome.google.com/webstore/detail/kimono/dhfegdhnpgbabihlegieihdhdijahimi?hl=ru
1. Находим сайт с необходимой нам информацией — то есть перечнем стран и их курортов. Открываем страницу, откуда необходимо получить данные.
2. Кликаем на иконку Kimono в правом верхнем углу Chrome.
3. Выделяем те части страницы, данные из которых нам необходимо спарсить. Если нужно выделить новый тип данных на той же странице, кликаем на «+» справа от «property 1» — так указываем Kimono, что эти данные нужно разместить в новом столбце.
Все страны на странице выделены с помощью Kimono (приложение Chrome)
4. Кликнув на фигурные скобки <> и выбрав «CSV», можно увидеть, как выбранные данные будут располагаться в таблице.

Предварительный просмотр расположения данных в таблице
5. Когда все данные отмечены:
- кликаем «Done» (в правом верхнем углу);
- логинимся в Kimono, чтобы привязать API к своему аккаунту;
- вводим название будущего АРI;
- кликаем «Create API».
Создаем новое API в Kimono
6. Когда API создано, переходим в таблицу Google, куда хотим загрузить выбранные данные. Выбираем «Connect to Kimono» и кликаем на название нашего API — «Resorts». Список стран и ссылок на страницы с курортными городами выгружается на отдельный лист.
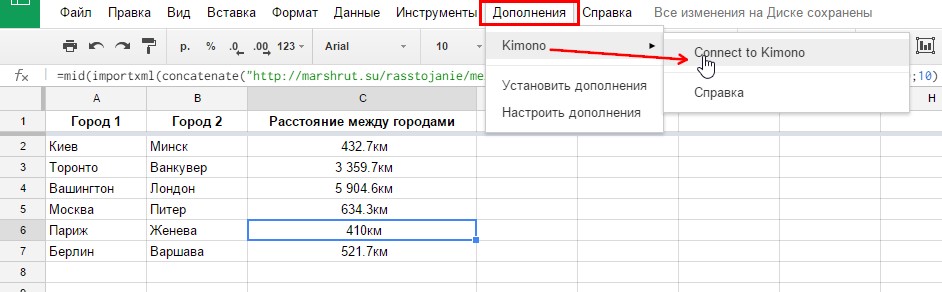
Синхронизируем Kimono с Google SpreadSheets
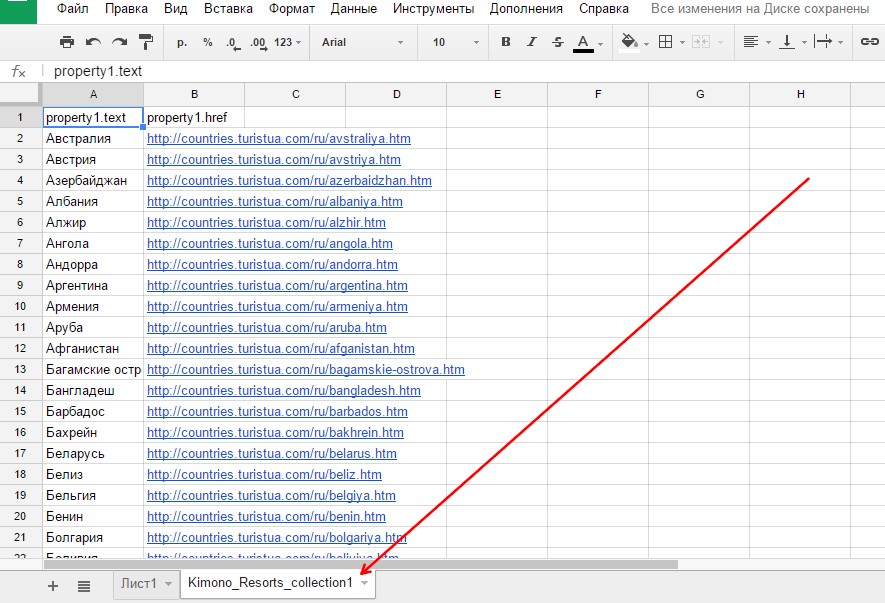
После синхронизации Kimono выгружает данные на отдельный лист
7. Переходим снова на сайт, берем для примера Ирландию, и снова выбираем через Kimono города, которые необходимо спарсить. Создаем API, называем его «Resorts in countries».

Задаем Kimono шаблон для парсинга
8. Переходим по ссылке в Kimono Labs. Теперь нам нужно спарсить список курортных городов по всем странам, а не только по Ирландии. Чтобы это сделать, переходим на вкладку «Crawl setup».
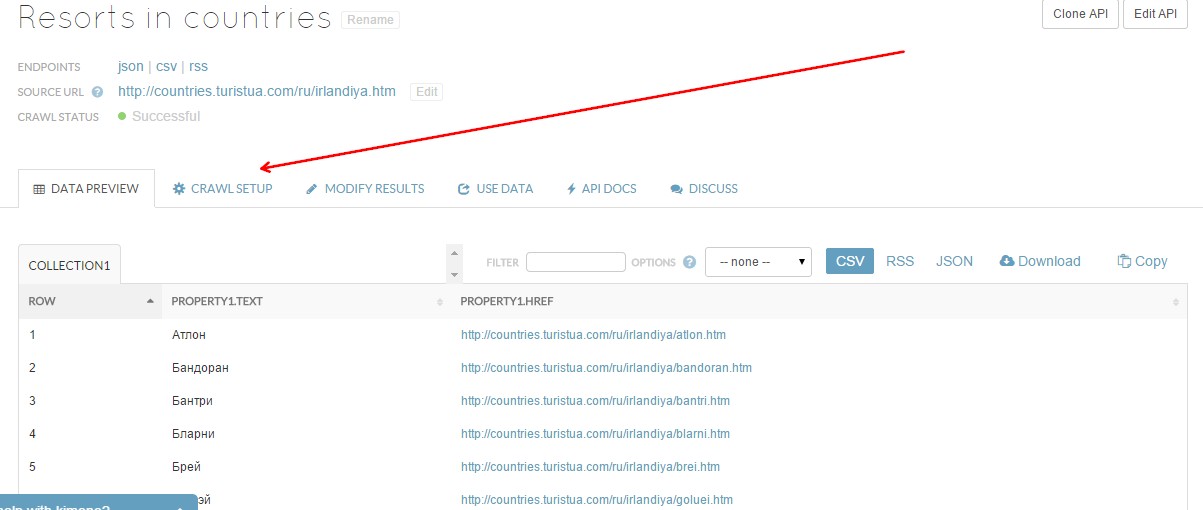
Расположение вкладки по настройкам обхода страниц в Kimono Labs
9. В «Crawl Strategy» выбираем «URLs from source API». Появляется поле с выпадающим списком всех API. Выбираем созданное нами ранее API «Resorts» и из него автоматически загружается список URL для парсинга. Кликаем синюю кнопку «Start Crawl» (начать обход) и следим за статусом парсинга. Kimono обходит страницы, парсит данные по заданному ранее шаблону и добавляет их в таблицу — то есть делает все то же самое, что и для Ирландии, но уже для всех других стран, что ввели автоматически и без нашего участия.
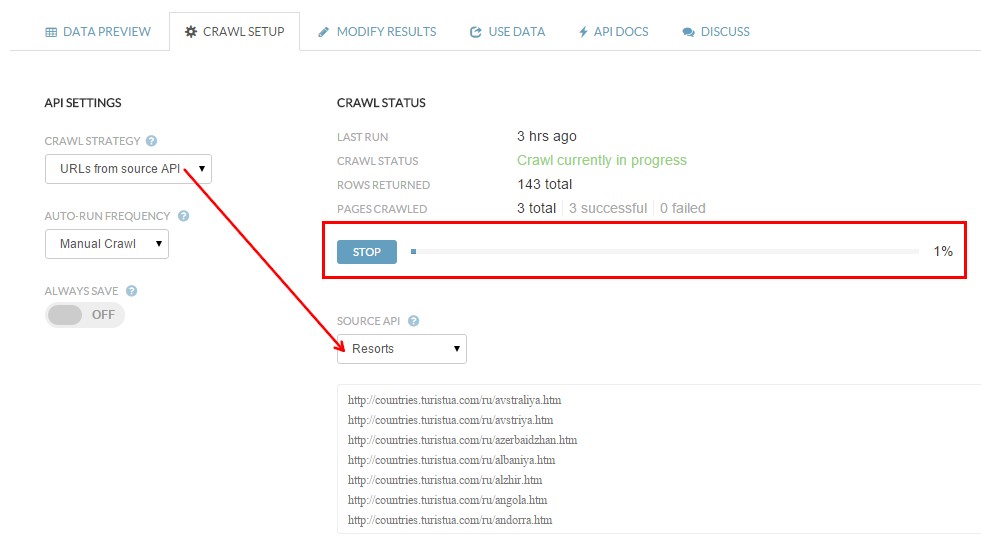
Как добавить в Kimono список URL для парсинга, используя уже существующий API
10. Когда таблица сформирована, синхронизируем Kimono Labs с таблицей Google — точно так же, как делали это в шестом пункте. В результате, в таблице появляется второй лист с данными.

Выгружаем полученные данные из Kimono Labs в Google SpreadSheets.
Предположим, хотим, чтобы в таблице отображались все курортные города в стране города прибытия. Данные на листах Kimono обрабатываем с помощью формул для таблиц Google, и выводим в строку список городов, где еще можно отдохнуть в Австралии, кроме Сиднея.
Например, это можно сделать так. Разметить массив данных (список городов), используя логические функции и возвращая значение ячейке, равное TRUE или FALSE. На примере ниже выделили для себя города, которые находятся именно в Австралии:
- TRUE = город находится в Австралии;
- FALSE = город находится в другой стране.

Выделение необходимой части данных из всего массива с помощью формул таблиц Google
По меткам TRUE определяем начало и конец обрабатываемого диапазона, и выводим в строку соответствующие этому диапазону города.

Конечная обработка данных
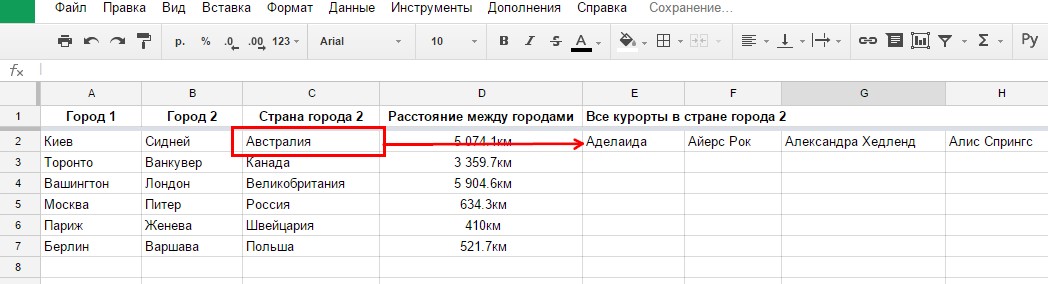
Отображаемый результат
По аналогии можем вывести курортные города и для других стран.
Мы специально привели здесь достаточно простой и пошаговый пример — формулу можно усложнить, например, сделать так, чтобы достаточно было ввести страну в колонку С, а все остальные вычисления и вывод городов в строку происходили автоматически.
https://chrome.google.com/webstore/search/scraper sheet?hl=ru&_category=extensions